Wer mich kennt, weiß: Ich liebe Automatisierung, die einfach funktioniert. Um ein Prinzip zu verdeutlichen, das mir gerade durch den Kopf geht, habe ich ein kleines Gedankenexperiment in n8n aufgebaut. Es ist ein fiktives Szenario, das aber ein reales Problem moderner Workflows auf den Punkt bringt. Ich habe zwei parallele Wege konstruiert, um nützliche Daten zu generieren.
Auf der einen Seite: Ein simpler Code-Node – mein "Fels in der Brandung". Er tut exakt das, was er soll, jedes Mal gleich, nahezu kostenlos. Auf der anderen Seite: Ein AI-Agent, befeuert durch OpenRouter. Das "kreative Chaos", das Lösungen findet, die man nicht hart codieren kann, aber eben auch eine gewisse Unberechenbarkeit mitbringt.
Mir kamen dann die Begriffe Stabil oben in Grün und Volatil unten in Gelb in den Sinn.
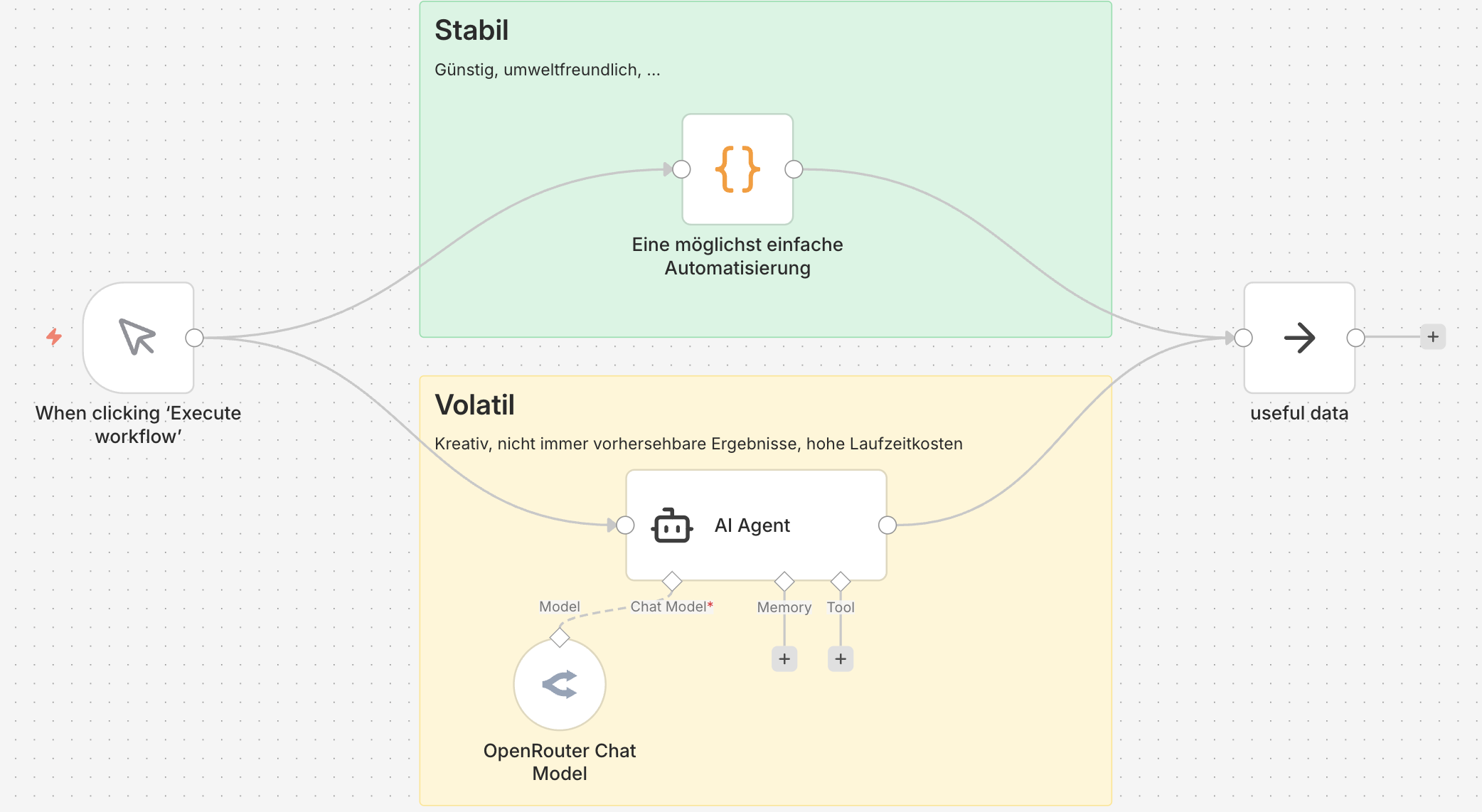
Zwei fiktive Wege in einem n8n Workflow
Das ist keine Wertung. Es ist eine Kategorisierung. Und genau darum geht es mir in diesem Post: Wann greife ich zu welchem Werkzeug – und warum?
Was "stabil" bedeutet
Klassische Automatisierung – also regelbasierte Systeme, Skripte, Code-Nodes, Regex – arbeitet deterministisch. Gleiche Eingabe, gleiches Ergebnis. Immer. Das klingt langweilig, ist aber in vielen Kontexten genau das, was ich brauche.
Nehmen wir ein konkretes Beispiel aus der Forschung: Bei der Extraktion von BI-RADS-Scores aus radiologischen Berichten (Röntgenbilder) wurde Regex direkt mit LLMs verglichen [1]. Die Genauigkeit? Nahezu identisch. Der Unterschied: Regex war 28.120-mal schneller. Nicht ein bisschen schneller. 28.000-mal. Das ist kein akademisches Detail – das ist ein Architektur-Argument.
Stabile Automatisierung ist auch aus Sicht der Betriebskosten attraktiv. Ein Code-Node in n8n kostet mich nichts extra. Ein LLM-Aufruf schon. Und bei jedem Zyklus wieder. Wer Workflows mit hohem Durchsatz betreibt, merkt das am Ende des Monats.
Was klassische Automatisierung braucht: saubere, strukturierte Daten und klar definierte Regeln. Wenn ich weiß, was rein geht und was raus kommen soll, ist ein Code-Node die überlegene Wahl. Keine Überraschungen, keine Halluzinationen, kein Token-Verbrauch.
Was "volatil" bedeutet – und warum das kein Fehler ist
KI ist nicht instabil. KI ist in einer gewissen Weise kreativ (KI im Sinne von Generative KI). Das ist ein wichtiger Unterschied.
Wenn ich einem AI Agent eine Aufgabe gebe, bekomme ich nicht zwingend das identische Ergebnis bei identischer Eingabe. Das klingt nach Nachteil – ist aber oft genau das, was ich brauche. Nämlich dann, wenn:
- die Eingabedaten unstrukturiert sind (Freitexte, E-Mails, PDFs ohne Schema)
- ich keine vollständigen Regeln definieren kann, weil die Varianz zu groß ist
- ich Kontext und Intention verstehen muss, nicht nur Muster matchen
Ein Beispiel: Ich möchte eingehende Support-Anfragen automatisch kategorisieren und priorisieren. Kein Regex der Welt kommt damit klar, wenn Kunden auf zwölf verschiedene Arten schreiben, dass ihr Shop-Login nicht funktioniert. Ein LLM versteht das – auch in holprigem Deutsch, mit Rechtschreibfehlern und ohne klare Struktur.
Das ist die Stärke der volatilen Seite. Kein Regelbuch nötig. Dafür: Laufzeitkosten, potenziell variierende Ergebnisse und – wichtig – höherer Ressourcenverbrauch.
Das Demokratisierungsproblem
Hier wird es interessant – und ehrlich gesagt auch ein bisschen heikel.
KI-Tools haben die Automatisierung demokratisiert. Wer früher einen Entwickler brauchte, um einen Workflow zu bauen, kann heute in n8n einen AI Agent hinwerfen, einen Prompt schreiben und loslegen. Das ist großartig. Im Prinzip.
In der Praxis sehe ich aber immer häufiger, dass Nicht-Techniker – und leider auch manche Dienstleister – AI Agents einsetzen, wo ein einfacher Code-Node die bessere Lösung wäre. Nicht aus Böswilligkeit, sondern weil:
- Der AI Agent "einfach funktioniert" – zumindest beim ersten Test
- Die Kosten und Konsequenzen erst später sichtbar werden
- Das Verständnis fehlt, was unter der Haube passiert
Konkret: Wer eine Bestellbestätigung per E-Mail versendet und dafür einen LLM-Aufruf macht, weil "das KI kann", zahlt sinnlose Token-Kosten für eine Aufgabe, die ein Template mit drei Variablen in Millisekunden löst. Sicher ist das nicht zwingend teuer – aber es skaliert schlecht. Und es ist fehleranfälliger: Was, wenn das Modell mal kreativ wird und den Inhalt der E-Mail leicht variiert?
Noch kritischer wird es bei sicherheitsrelevanten Prozessen. KI-generierter Output ist kein deterministischer Output. Wer das in Berechtigungsprüfungen einbaut, ohne das zu verstehen, baut sich ein Problem auf Vorrat.
Schon im Jahr 2020 haben Kollegen von mir bei einer Studie in Deutschland große Defizite bei Expertise zu KI, Prozessoptimierung und Automatisierung [2] festgestellt. Ob wir jetzt in 2026 viel besser darstehen?
Ressourcen, Kosten, Geschwindigkeit
Ein paar Zahlen, die ich im Hinterkopf behalte:
- Ein einfacher Code-Node: nahezu keine Laufzeitkosten, Ausführung in Millisekunden
- Ein LLM-Aufruf via API: Token-Kosten, die sich bei hohem Durchsatz summieren – und das nicht linear, sondern kumulativ, weil bei Multi-Turn-Konversationen der gesamte Verlauf mitbezahlt wird
- Reasoning-Modelle (die mit explizitem "Thinking"): bis zu 50-facher CO₂-Ausstoß gegenüber kompakten Modellen – für oft marginale Genauigkeitsgewinne [3]
Das bedeutet nicht, KI zu vermeiden. Es bedeutet, bewusst zu wählen. Brauche ich wirklich ein Reasoning-Modell für das Taggen von Blog-Posts? Nein. Reicht ein kleineres, schnelles Modell für die Sentiment-Klassifikation von Kundenbewertungen? Ja, in den meisten Fällen.
In meinem privaten n8n habe ich die Metriken immer im Blick.
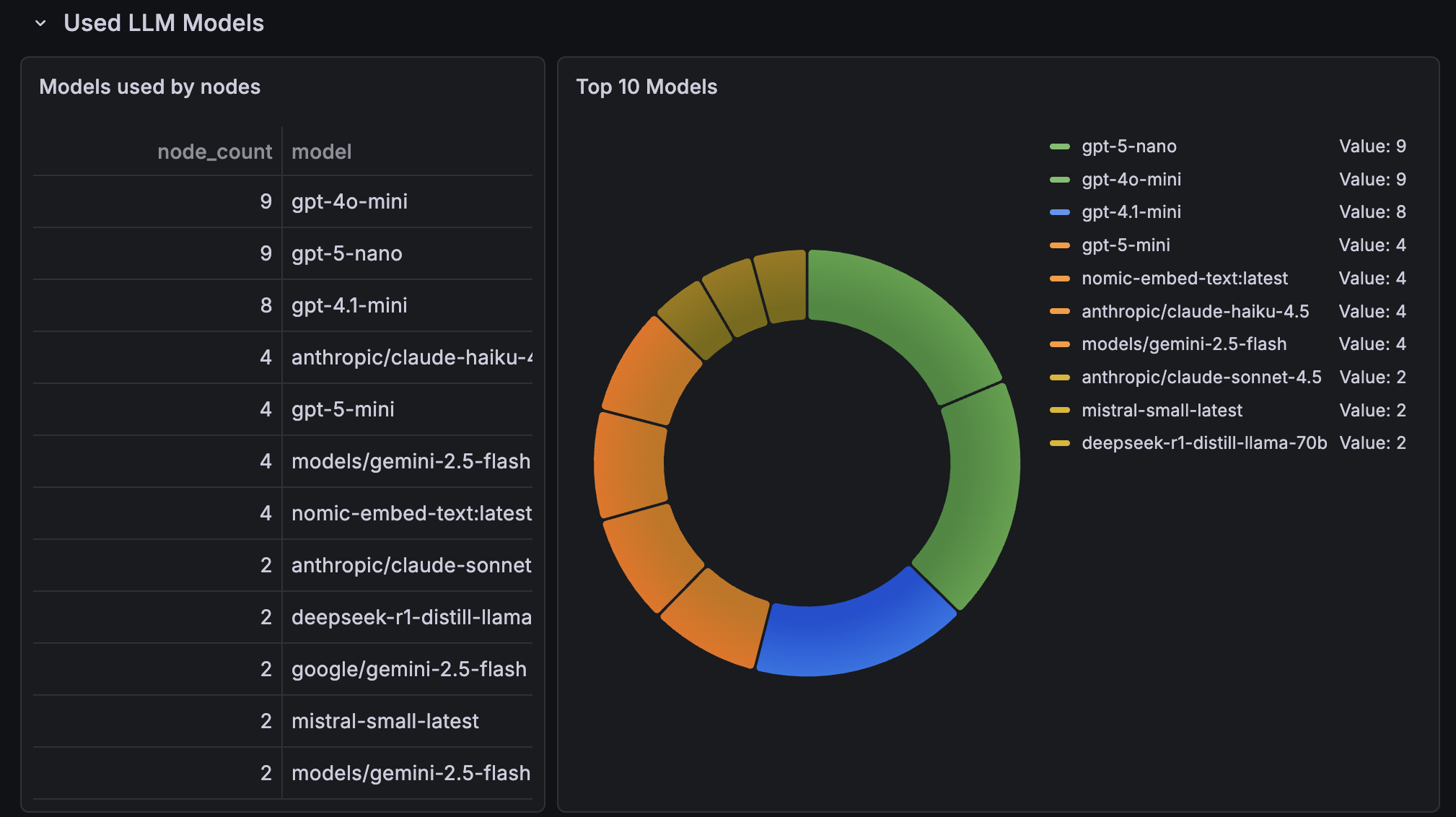
Dashboard in Grafana
Die meisten meiner n8n Prozesse sind immer noch klassisch ohne KI oder nur an gewissen Stellen mit KI ergänzt. Es gibt aber auch Workflows die nur auf KI basieren.
Wann ich zur KI muss
Es gibt Aufgaben, bei denen ich mit klassischer Automatisierung schlicht nicht weiterkomme:
- Unstrukturierte Eingaben verstehen – Freitexte, OCR-Ergebnisse, gescannte Dokumente
- Inhaltliche Bewertung – Ist diese Produktbeschreibung vollständig? Klingt dieser Text professionell?
- Kontextabhängige Entscheidungen – Was ist die passende Antwort auf diese Kundenfrage, abhängig von Bestellhistorie und aktuellem Kontext?
- Kreative Aufgaben – Texte generieren, variieren, übersetzen, zusammenfassen
Für alles davon gibt es keine Regex. Kein if-else-Baum wächst hoch genug. Hier ist KI nicht die bequeme Option – sie ist die einzig sinnvolle.
Der hybride Weg: Determinismus als Leitplanke
Meine persönliche Architektur-Präferenz sieht so aus: deterministischer Rahmen, KI dort wo nötig [4].
In n8n bedeutet das konkret: Ich prüfe zuerst, ob ich ein Problem regelbasiert lösen kann. Wenn ja, Code-Node. Wenn nein, AI Agent – aber mit klaren Leitplanken: definierten Eingabeformaten, validierten Ausgaben, und einem deterministischen Weiterverarbeitungsschritt danach.
Das Diagramm am Anfang dieses Posts zeigt genau das: Beide Wege laufen in denselben Output. Ich entscheide pro Aufgabe, welcher Pfad sinnvoller ist. Das ist keine Entweder-oder-Frage. Es ist eine Designentscheidung.
Wo steckt bei mir überall KI drin?
Wichtig finde ich auch, dass man seine KI-Prozesse im Blick hat. Auch diese benötigen eine Wartung und müssen immer mal wieder angepasst werden. Gerade, wenn neue Modelle auf den Markt kommen.
In meinen Fall habe ich verschiedene Dashboards in meinen Grafana erstellt. Unter anderem eines, dass mir eine Übersicht der in den n8n Workflows genutzten Modelle und Provider bietet.

Metriken in n8n
Gelöst habe ich das über einen n8n Workflow der mir täglich alle anderen Workflows analyisiert und die Metadaten dann in meiner Postgres Datenbank abgelegt.
Eine weiterer wichtiger Teil ist, dass man seine KI Modelle auch mit Testdaten testet. Dazu gibt es aber bestimmt mal einen eigenen Blog-Post von mir.
Fazit
KI ist kein Allheilmittel – und klassische Automatisierung ist kein Relikt. Beides hat seinen Platz. Die Kunst liegt darin zu erkennen, welches Werkzeug für welche Aufgabe geeignet ist [5].
Was mich bei der aktuellen Entwicklung beschäftigt: Immer mehr Menschen automatisieren, ohne die Implikationen zu verstehen. Das ist erst mal gut – Automatisierung ist wichtig. Aber die Wahl des falschen Werkzeugs produziert Systeme, die teurer, langsamer, fehleranfälliger und schwerer wartbar sind als nötig.
Meine Faustregel: Wenn ich das Problem vollständig beschreiben kann, brauche ich keine KI. Wenn nicht – dann schon.
Literatur
[1] Lacoste et al. (2025): A Comparative Performance Analysis of Regular Expressions and an LLM-Based Approach to Extract the BI-RADS Score from Radiological Reports. medRxiv.
https://www.medrxiv.org/content/10.1101/2025.06.01.25328636v1.full-text
[2] valantic (2020): Exklusive valantic-Studie: Große Defizite bei Expertise zu KI, Prozessoptimierung und Automatisierung
https://www.valantic.com/de/presse/exklusive-valantic-studie-mit-luenendonk/
[3] ScienceDaily (2025): Thinking AI models emit 50x more CO2 — and often for nothing.
https://www.sciencedaily.com/releases/2025/06/250619035520.htm
[4] Elementum AI (2025): Deterministic vs. Probabilistic AI: Enterprise Workflow Guide.
https://www.elementum.ai/blog/deterministic-vs-probabilistic-ai
[5] ECI Software Solutions: AI vs. Automation: Why the Difference Matters for SMB Growth.
https://www.ecisolutions.com/blog/ai-vs-automation-smb-difference/